
出自于论文“Point Pair Feature-Based Pose Estimation with Multiple Edge Appearance Models (PPF-MEAM) for Robotic Bin Picking”
针对多边的树脂工件的改进PPF

出自于论文“Point Pair Feature-Based Pose Estimation with Multiple Edge Appearance Models (PPF-MEAM) for Robotic Bin Picking”
针对多边的树脂工件的改进PPF
论文:Going Further with Point Pair Features
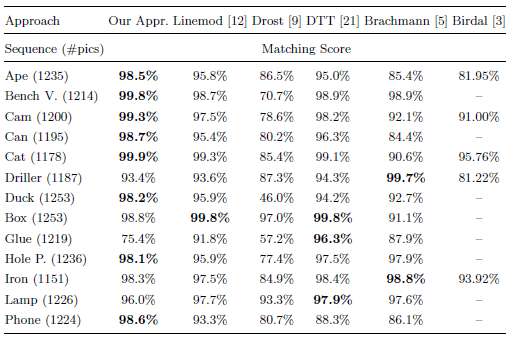
linemod作者改进2010的Drost-PPF,使得改进PPF在2016年的“state of the art”。在下面数据集中,本文方法只使用了深度数据,而[12][5][21]使用了彩色数据,还是在13种类别中,在8个类别里面获得了最高分。
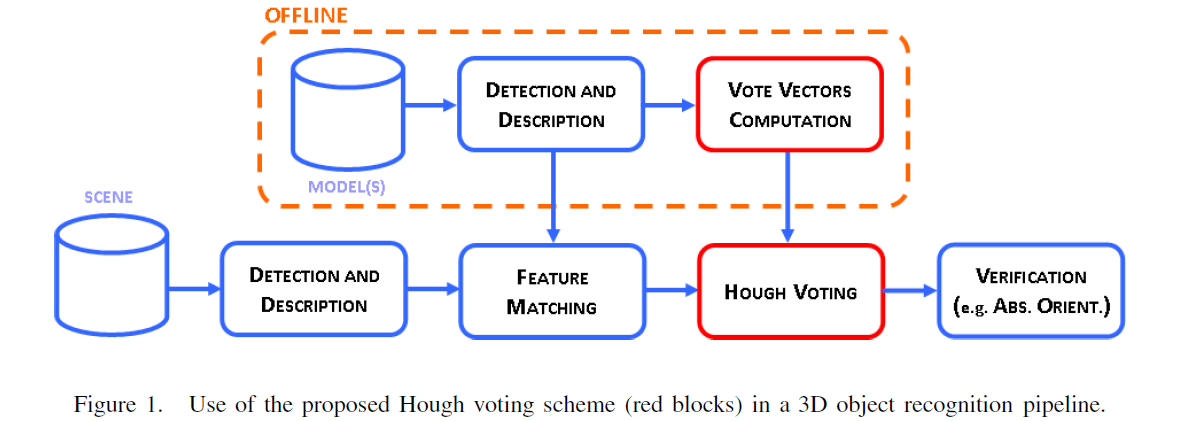
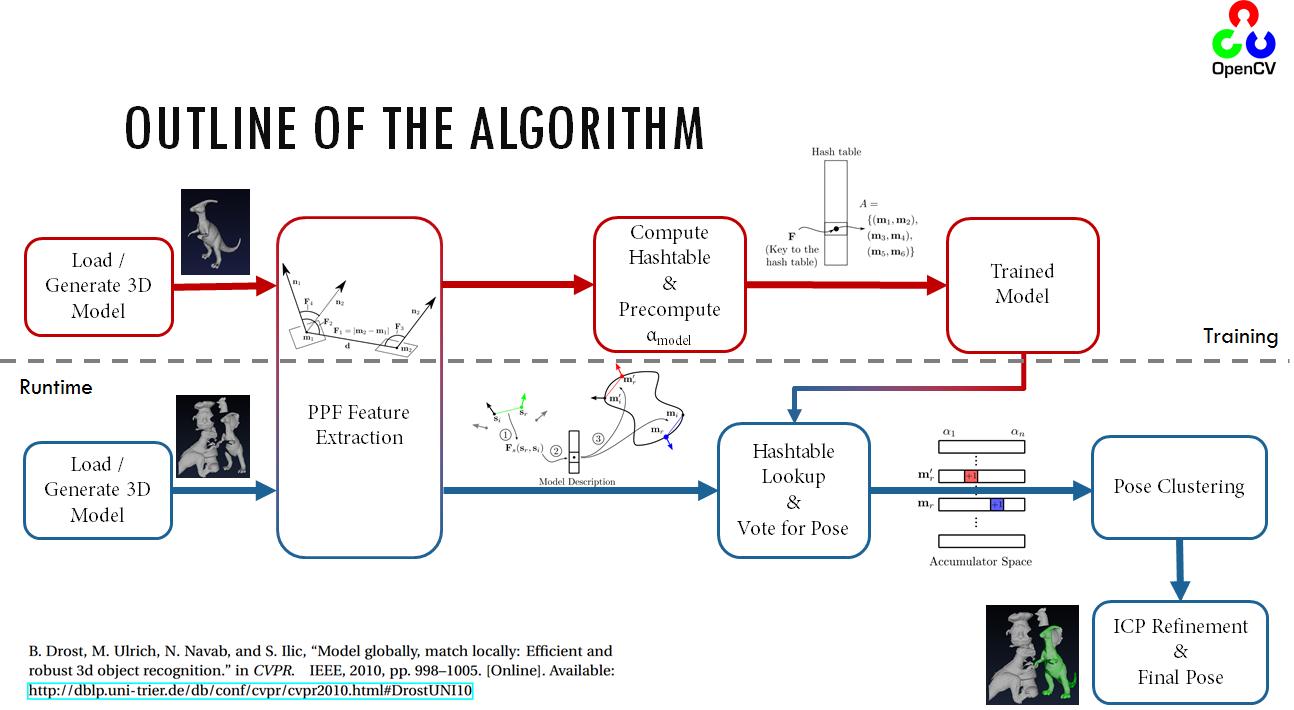
1.PPF在三维物体识别与位姿估计算法中表现优异,本文是论文“Model Globally, Match Locally: Efficient and Robust 3D Object Recognition”的解读
2.PPF是halcon中surface_matching算子实现原理
3.PPFoutline
视觉SLAM中大量使用了SfM中的方法,如特征点跟踪、捆集优化(Bundle Adjustment)等,以至于许多研究者把它们视为同一个研究领域。然而,尽管方法上很相似,SLAM和SfM的侧重点是不同的。SLAM的应用场合主要在机器人和VR/AR,计算资源有限,需要很强的实时性,故侧重点在于,如何在有限的资源里快速地对相机进行定位。而SfM方法通常是离线的,可以调用大量计算资源进行长时间的计算,侧重于重建出更精确、美观的场景。
SFM中我们用来做重建的点是由特征匹配提供的!这些匹配点天生不密集!
而MVS则几乎对照片中的每个像素点都进行匹配,几乎重建每一个像素点的三维坐标,这样得到的点的密集程度可以较接近图像为我们展示出的清晰度。
其实现的理论依据在于,多视图照片间,对于拍摄到的相同的三维几何结构部分,存在极线几何约束。
描述这种几何约束:
想象,对于在两张图片中的同一个点。现在回到拍摄照片的那一刻,在三维世界中,存在一条光线从照片上这一点,同时穿过拍摄这张照片的相机的成像中心点,最后会到达空间中一个三维点,这个三维点同时也会在另一张照片中以同样的方式投影。
这个过程这样看来,很普通,就如同普通的相机投影而已。但是因为两张图片的原因,他们之间存在联系,这种联系的证明超过了能力范围,但是我们只需要知道,此种情况下,两张照片天然存在了一种约束
DeepSFM:通过深度BA进行SFM(运动推断结构) 《DeepSFM: Structure From Motion Via Deep Bundle Adjustment》
DeepSFM性能优于BANet、LS-Net和COLMAP等网络
Update your browser to view this website correctly. Update my browser now