
SSE指令集入门教程
unordered_map是非线程安全的,应该如何处理多线程情况
CPU多线程
GPU多线程
[thrust::system::system_error]
1 | cudaMalloc((void**)&nanFlags_dev, N*sizeof(int)); |
出现错误:
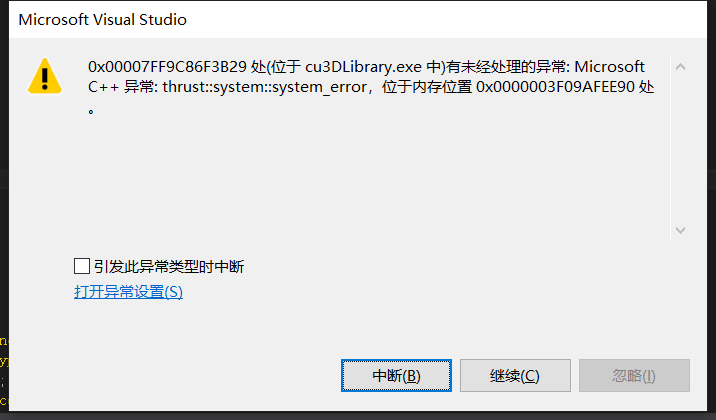
原因:核函数getNANpts写错了。只对nanFlags_dev中的一个位置进行初始化,其他位置没有赋值,所以进行计算时会错误。
Update your browser to view this website correctly. Update my browser now