

神经网络与深度学习(Neural Networks and Deep Learning)读书笔记
深度学习框架
TensorFlow (主流);Keras; Caffe;PyTorch (上升很快);Theano ;MXNet ;Chainer ;CNTK
第一章:基本概念
1. 感知器(perceptron)/也叫神经元
感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。
感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改权重和偏置,直到训练完成。(另外一种说法:设计学习算法,能够自动调整人工神经元的权重和偏置)。
2. S型神经元(sigmoid)
激活函数
简单理解:简单来说,人工神经元计算输入的“加权和”,加上偏置(总的偏置) = Y,接着决定是否需要“激活”(好吧,其实是激活函数决定是否激活,但是现在让我们先这样理解吧)。
几种激活函数:将Y输入激活函数,获得输出
阶跃函数
当值大于0(阈值)时,输出为1(激活),否则输出为0(不激活)。
只能输出是或者否
因为我们希望输出中间(模拟)激活值,而不是仅仅输出“激活”或“不激活”(二元值)。
线性函数
线性激活函数将给出一定范围内的激活,而不是二元激活。我们当然可以连接若干神经元,如果不止一个神经元激活了,我们可以基于最大值(max或softmax)做决定。
问题:
线性函数的导数是个常数。常数怎么训练?不管我们有多少层,如果这些层的激活函数都是线性的,最后一层的最终激活函数将是第一层的输入的线性函数!这将使得我们找不到目标函数的迭代方向。
我们需要非线性的激活函数!
sigmoid function
阶跃函数平滑后的版本,它是非线性的。这意味着该函数的组合也是非线性的。它将给出模拟激活,而不是0或1,它趋向于将激活导向曲线的两边。这在预测上形成了清晰的差别。
问题:
越是接近sigmoid的两端,相对X的改变,Y就越趋向于作出非常小的反应。这意味着在该区域的梯度会很小。也就是“衰减的梯度”问题 。网络拒绝进一步学习,或者学习速度剧烈地变慢了(取决于具体案例,直到梯度/计算碰到了浮点值的限制)。不过,我们有一些变通措施,因此在分类问题中,sigmoid仍旧非常流行。
tanh function
这是一个经过拉升的sigmoid函数。tanh的性质和我们之前讨论的sigmoid类似。它是非线性的,因此我们可以堆叠网络层。它是有界的
(-1, 1),所以不用担心激活膨胀。值得一提的是,tanh的梯度比sigmoid更激烈(导数更陡峭)。因此,选择sigmoid还是tanh将取决于你对梯度强度的需求。和sigmoid类似,tanh也存在梯度衰减问题。ReLU
修正线性单元:
乍看起来这和线性函数有一样的问题,因为在正值处它是线性的。首先,RuLu是非线性的。ReLu的组合也是非线性的!(实际上它是一个很好的逼近子。ReLu的组合可以逼近任何函数。)很好,这意味着我们可以堆叠网络层。不过,它并不是有界的。ReLu的值域是
[0, inf)。这意味着它将膨胀激活函数。ReLu的水平线部分(X的负值)意味着梯度会趋向于0。当激活位于ReLu的水平区域时,梯度会是0,导致权重无法随着梯度而调整。这意味着,陷入此状态的神经元将停止对误差/输入作出反应(很简单,因为梯度是0,没有什么改变)。这被称为死亡ReLu问题。这一问题会导致一些神经元直接死亡、失去响应,导致网络的很大一部分进入被动状态。有一些缓和这一问题的ReLu变体,将水平线转为非水平部分,例如,当x<0时y = 0.01x,使图像从水平线变为略微倾斜的直线。这就是弱修正ReLu(leaky ReLu)。还有其他一些变体。主要的想法是让梯度不为零,这样网络可以逐渐从训练中恢复。
相比tanh和sigmoid,ReLu在算力上更经济,因为它使用的是比较简单的数学运算。
该选哪个?
当我们知道尝试逼近的函数具有某些特定性质时,我们可以选择能够更快逼近函数的激活函数,从而加快训练过程。例如,sigmoid对分类器而言很有效(看看sigmoid的图像,是不是展示了一个理想的分类器的性质?),因为基于sigmoid的组合逼近的分类函数要比诸如ReLu之类的函数更容易。
如果你并不清楚试图学习的函数的本质,那我会建议你从ReLu开始,然后再试其他。在大多数情况下,ReLu作为一个通用的逼近子效果很不错。
3. 神经网络架构
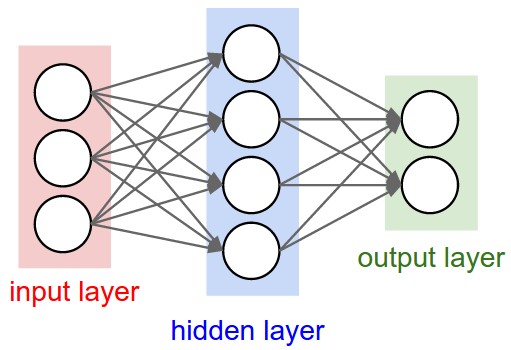
神经网络其实就是按照一定规则连接起来的多个神经元。上图展示了一个全连接(full connected, FC)神经网络,通过观察上面的图,我们可以发现它的规则包括:
- 神经元按照层来布局。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层,因为它们对于外部来说是不可见的。
- 同一层的神经元之间没有连接。
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入。
- 每个连接都有一个权值。
4. 使用梯度下降法进行学习
神经网络学习算法:用来计算目标函数找到合适的权重和偏置,使得目标函数的数值≈0
- 动量随机梯度下降法(SGD)
- RMSprop算法
- Adam算法(自适应矩估计)
- 遗传算法
随机梯度下降算法(Stochastic Gradient Descent, SGD)
- 要遍历训练数据中所有的样本进行计算,我们称这种算法叫做批梯度下降(Batch Gradient Descent)
- 实用的算法是SGD算法。在SGD算法中,每次更新w的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对w更新数百万次,虽然存在一定随机性,大量的更新总体上沿着减少目标函数值的方向前进的,因此最后也能收敛到最小值附近。
- SGD不仅仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
第二章:反向传播算法如何工作
反向传播算法:一种快速计算代价函数的梯度的方法
第三章:改进神经网络的学习方法
3.1 交叉熵代价函数
二次代价函数改成交叉熵代价函数(神经元在犯错误时学习得更快)
我们大多数情况会使用交叉熵代价函数来解决学习缓慢的问题,但是还有一种方法:基于柔性最大值(softmax)神经元
3.2 过拟合和规范化
防止过拟合:
使用验证集来代替测试机防止过拟合问题
增加训练样本数量
规范化:又称权重衰减或者L2规范化
即对代价函数进行规范化,交叉熵代价函数进行L2规范化。
局部相应规范化(Local Responsible Normalization, LRN):
使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率。
弃权(drop out)
选择性地忽略训练中的单个神经元,避免模型的过拟合认为扩展训练数据
3.3 权重初始化
- 之前的方式就是根据独立高斯随机变量来选择权重和偏置。
- 使用归一化的高斯分布做得更好。
3.5 如何选择神经网络的超参数
超参数:开始学习之前设置的参数
3.6 其他技术
第四章:神经网络可以计算任何函数的可视化证明
4.1 两个预先声明
4.2 一个输出和一个输入的普遍性
4.3 多个输入变量
4.4 S型神经元的延申
4.5 修补阶跃函数
第五章:深度神经网络为何很难训练
5.1 梯度消失问题
5.2 什么导致消失的梯度问题?神经网络中的梯度不稳定性
5.3 在更加复杂网络中的不稳定梯度
5.4 其它深度学习的障碍
第六章:深度学习
1. 介绍卷积网络
2. 卷积网络在实际中的应用
神经网络各层分析
1.卷积Convolution
2.池化Pooling
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。
Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在n*n的样本中取最大值,作为采样后的样本值。下图是2*2 max pooling:
