

第四章 CUDA C 并行编程、第五章线程协作
CUDA C并行编程、线程协作、GPU逻辑结构、配置线程、共享内存与同步、二维线程块实现波纹、共享内存实现点积
建议下载下来用Typora软件阅读markdown文件
作者github:littlebearsama 原文链接
(建议下载Typora来浏览markdown文件)
第四章 CUDA C 并行编程
1 | #include<stdio.h> |
- 调用cudaMalloc()在设备上为三个数组分配内存。
- 使用完GPU后调用cudaFree()来释放他们。
- 通过cudaMemcpy()进行主机与设备之间复制数据。
第五章 线程协作
1.GPU逻辑结构
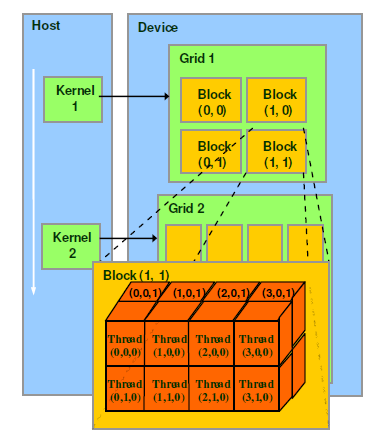
CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread)组成,
相当于把GPU上的计算单元分为若干(2~3)个网格,
每个网格内包含若干(65535)个线程块,
每个线程块包含若干(512)个线程,
三者的关系如下图:
2.线程索引(ID)定位
作用:
线程ID用来定位线程,根据线程ID来给各个线程分配数据以及其他操作。
计算线程ID需要通过本线程的各个内建变量来计算被调用核函数所进入的线程ID.
内建变量:
threadIdx(.x/.y/.z代表几维索引):线程所在block中各个维度上的线程号
blockIdx(.x/.y/.z代表几维索引):块所在grid中各个维度上的块号
blockDim(.x/.y/.z代表各维度上block的大小):
block的大小即block中线程的数量,
blockDim.x代表块中x轴上的线程数量,
blockDim.y代表块中y轴上的线程数量,
blockDim.z代表块中z轴上的线程数量
gridDim(.x/.y/.z代表个维度上grid的大小):
grid的大小即grid中block的数量,
gridDim.x代表grid中x轴上块的数量,
gridDim.y代表grid中y轴上块的数量,
gridDim.z代表grid中z轴上块的数量
定义grid、block大小:
dim3 numBlock(m,n)
dim3 threadPerBlock(i,j)
则blockDim.x=i; blockDim.y=j; gridDim.x=m; gridDim.y=nkernel调用:
kernel<<<numBlock,threadPerBlock>>>(a,b)
这是调用kernel时的参数,尖括号<<<>>>中第一个参数代表启动的线程块的数量,第二个参数代表每个线程块中线程的数量。总的线程号:
设线程号为tid,以下讨论几种调用情况下的tid的值,这里只讨论一维/二维的情况一维:
1.kernel<<<1,N>>>()
block和thread都是一维的,启动一个block,里面有N个thread,1维的。tid=threadIdx.x2.kernel<<<N,1>>>()
启动N个一维的block,每个block里面1个thread。tid=blockIdx.x3.kernel<<<M,N>>>()
启动M个一维的block,每个block里面N个一维的thread。tid=threadIdx.x+blockIdx.x * blockDim.x
一般如何配置线程?
kernel<<<M,N>>>() M,N为1维度
输入数据numbers,设定每个线程块有N=128或256或512个线程,一般设为128。
计算应该设置的线程块M=(numbers+N-1)/N,向上取整;线程块是数量不能超过65535,这是一种硬件限制,如果启动的线程块数量超过了这一限值,那么程序将运行失败。
二维:
dim3 grid(4, 4, 1), block(4, 4, 1);
一维索引:
1 | __global__ void vector_add(float* vec1, float* vec2, float* vecres, int length) { |
二维索引:
1 | __global__ void vector_add(float** mat1, float** mat2, float** matres, int width) { |
tid<N
公式M=(numbers+N-1)/N保证了启动了足够多的线程,当输入数据numbers不是线程块里面线程数N的整数倍时,将启动过多线程。
为了防止启动过多线程:在核函数中,在访问输入数组和输出数组之前,必须检查线程的偏移(索引)tid是否位于0到N之间
1 | if(tid<N) |
因此,当索引越过数组边界时,例如当启动并行线程数量不是线程块中线程的数目N(128)就会出现这种情况,那么核函数将自动停止执行计算。更重要的是,核函数不会对越过数组边界的内存进行读取或写入。
- 简单来说就是启动了充足的线程,而有的线程不用工作,为了防止核函数不会出现越界读取等错误,我们使用了条件判断if(tid<N)。
当数据大于运行线程时
因为数据数目大于线程数目,所以正在运行的所有线程都可能会再被执行,直到所有数据处理完毕。所以while(tid<N)不仅仅用于判断线程ID tid,是否执行线程。也用于循环。
添加语句tid+=blockDim.x*gridDim.x;增加的值等于每个线程块中的线程数量乘以线程网格中线程块的数量,在上面的线程分配(一维的线程格,一维的线程块)中为blockDim.x*gridDim.x
故核函数被改写为
1 | __global__ void add( int *a, int *b, int *c ) { |
3.二维的线程格,二维的线程块(实现波纹效果)
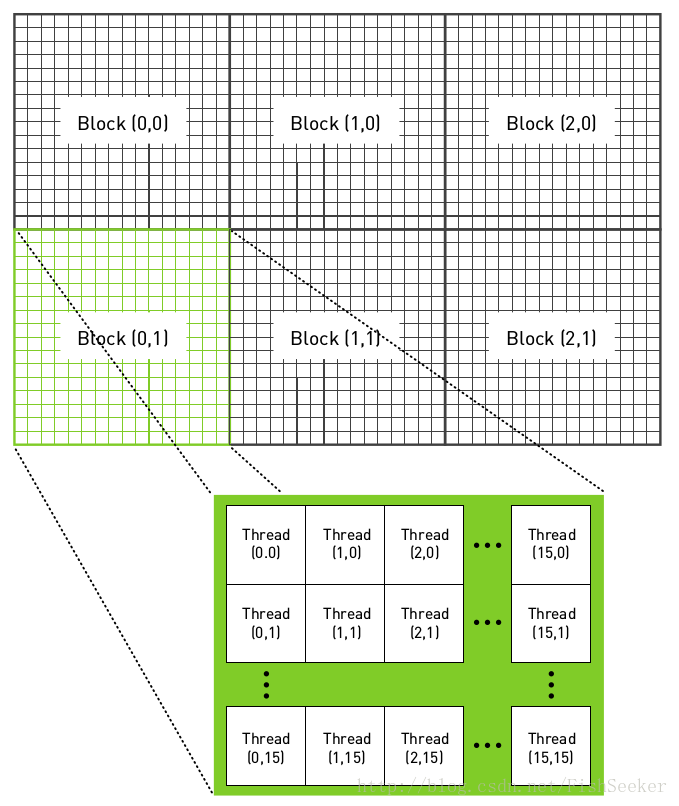
1 | __global__ void kernel( unsigned char *ptr, int ticks ) { |
- blocks和threads是两个二维变量
- 由于生成的是一幅图像,因此使用二维索引,并且每个线程都有唯一的索引
(x,y),这样可以很容易与输出图像中的像素一一对应起来。就是输出图像的像素索引(x,y) - offset是数据的线程索引(被称为全局偏置),该线程对应图像像素索引(x,y)也对应数据索引offset
(fx,fy)=像素点(x,y)相对于图像中心点(DIM/2,DIM/2)位置,即把图像原点移到图像中心- 加入线程块是一个16X16的线程数组,图像有DIMXDIM个像素,那么就需要启动DIM/16 x DIM/16个线程块,从而使每一个像素对应一个线程。
- GPU优势在于处理图像时比如1920X1080需要创建200万个线程,CPU无法完成这样的工作。
4.共享内存和同步
- 共享内存术语Shared Memory,是位于SM(流多处理器)中的特殊存储器。还记得SM吗,就是流多处理器,大核是也。
- 将关键字
__share__添加到变量声明中,这将是这个变量驻留在共享内存中。 - block与block的线程无法通信
- 共享内存缓存区驻留在物理GPU上,而不是驻留在GPU以外的系统内存中。因此,在访问共享内存时的延迟要远远低于访问普通缓存区的延迟,使得共享内存像每个线程块的高速缓存或中间结果暂存器那样高效。
- 想要在线程之间通信,那么还需要一种机制来实现线程之间的同步,例如,如果线程A将一个值写入到共享内存,并且我们希望线程B对这个值进行一些操作,那么只有当线程A写入操作完成后,线程B才能开始执行它的操作。如果没有同步,那么将发生竞态条件。
这里的例子是点积的例子,就是: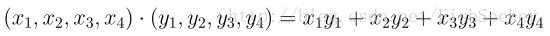
代码:
1 | __global__ void dot(float *a, float *b, float *c) { |
__shared__float cache[threadsPerBlock];在共享内存中申请浮点数组,数组大小和线程块中线程数目相同每个线程块都拥有该共享内存的私有副本。- 共享内存缓存区cache将保存该block内每个线程计算的加和值。
__syncthreads();等待线程块里面的所有线程执行完毕,简称线程同步。确保线程块中的每个线程都执行完__syncthreads();前面的语句后才会执行下一语句。- 用规约运算,我们取threadsPerBlock的一半作为i值,只有索引小于这个值的线程才会执行。只有当线程索引小于i时,才可以把cache[]的两个数据项相加起来。
__syncthreads()作用如下图(下图中是等待4个线程中的相加操作完成)。
假设cache[]中有8个元素,因此i的值为4。规约运算的其中一个步骤如下图所示
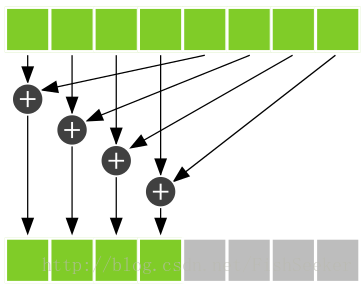
- 由于线程块之间无法通信。只能将每个线程块算出来的值存出来,存到数组c中,最后会返回block数量个c,然后由cpu执行最后的加法。
- 当某些线程需要执行一条指令,而其他线程不需要执行时,这种情况就称为线程发散(Thread Divergence)。在正常环境中,发散的分支只会使得某些线程处于空闲状态,而其他线程将执行分支中的代码。但是在
__syncthreads()情况中,线程发散造成的结果有些糟糕。CUDA架构将确保,除非线程块中的每个线程都执行了__syncthreads(),否则没有任何线程能执行__syncthreads()之后的指令。如果__syncthreads()位于发散分支中,一些线程将永远无法执行__syncthreads()。硬件将一直保持等待。 - 下面代码将使处理器挂起,因为GPU在等待某个永远无法发生的事件。
1 | if (cacheIndex < i){ |
- 例子2(二维线程布置)基于共享内存的位图(略)